Evals
AI performance measured on real comp workflows
Compa Evals are your system for measuring how reliably AI agents perform compensation work so you deploy AI with confidence, clarity, and control.




Trusted by compensation leaders managing billion-dollar portfolios
In compensation,
“mostly right” is still wrong
AI demos look impressive, but comp teams are left guessing about reliability, hidden risks, and the defensibility of outputs to business partners.
Compa Evals separate observability from evaluation
Observability tells you what the AI did. Evaluation tells you if it did the job well.
Compa Evals keeps those signals separate, so output quality isn’t diluted by speed, volume, or cost.

Real compensation prompts
Prompts come directly from enterprise comp workflows like market analysis, employee benchmarking, segmentation, and edge cases.
Outputs scored by comp experts
Human compensation experts evaluate AI outputs against four categories: accuracy, completeness, assumptions, and usability.
Ensure comparability across releases
See agent improvements, limitations, and how changes impact compensation proficiency.
Evaluations happen in a controlled environment so results stay comparable across releases. You control for context, tools, and configuration.
Outputs are consolidated into reliability scorecards for each compensation workflow and tracked over time.
A reliability scorecard built for enterprise scrutiny
Every compensation workflow comes with a reliability score, tracked over time and tied directly to comp work.
Scores are published, updated, and tested under constraints. If a score is ever 100%, it would mean we aren’t testing hard enough.
AI reliability you can track
The Comp Fundamentals Benchmark evaluates and tests the agent on the same compensation scenarios to measure the consistency of its judgment.
As Analyst Agent improves across data integrations, tooling, and system design, its benchmark score increases.
.png)
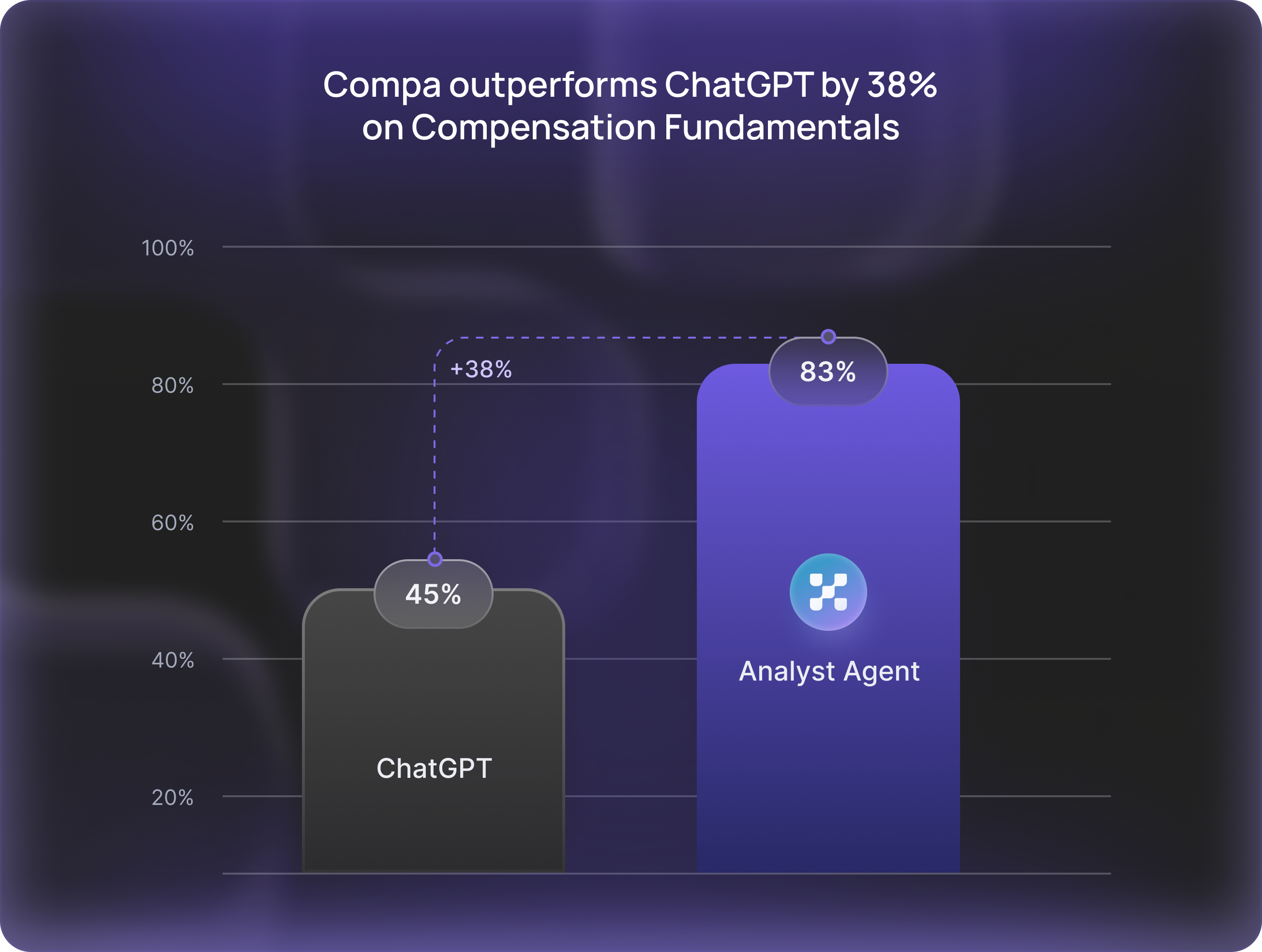
A benchmarked score for compensation fundamentals
Our Analyst Agent is evaluated against a standardized set of compensation fundamentals, designed to reflect the work of a real compensation analyst.
We run the same evaluation framework across models to produce a single, comparable score — making strengths and gaps explicit, not assumed.
What your peers say

“It’s what we all hoped agents would deliver: better, faster, more precise answers we can use for high-stakes decisions. We’re no longer reactive; we’re empowered.”

“We believe Compa is one of those tools that will enable us to make multi-billion dollar business decisions with the highest degree of confidence.”


“Analyst Agent is groundbreaking in the compensation industry, I’m amazed.”
